
Your blog ranks. Your traffic looks healthy. Google Search Console shows impressions climbing every month. And yet, when you type your own target question into ChatGPT or Google AI Overviews, your brand is nowhere in the answer. A competitor you’ve outranked for years shows up instead – sometimes citing worse content than yours.
This isn’t a fluke, and it isn’t a ranking problem. It’s a new failure mode that AEO and GEO practitioners now call “found but not cited.” Your page gets pulled into the AI’s retrieval pipeline – the model “sees” it – but it never earns a place in the final answer. No link, no brand mention, no credit.
This article breaks down why that happens, what the latest research says about it, and exactly what to fix in your content so it stops happening.
Found, Cited, or Mentioned? The Three States of AI Visibility
Before diagnosing the problem, it helps to separate three outcomes a page can land on inside a generative search system:
- Found (retrieved): The AI’s retrieval system pulls your URL into its working context. This is invisible to the end user – it happens entirely behind the scenes.
- Cited: The AI attaches a clickable link or footnote to a specific claim in its answer, pointing back to your page.
- Mentioned: The AI names your brand or product in the body of its response, with or without a link attached.
A page that’s “found but not cited” cleared the retrieval filter but failed the evaluation step that decides who gets credit. And according to Ahrefs’ analysis of 1.4 million ChatGPT prompts, this happens to roughly half of everything the model retrieves – ChatGPT pulls in dozens of URLs per query but ends up citing only about 50% of them.
The Citation Pipeline: Why Retrieval Doesn’t Guarantee Credit
Generative engines don’t read your page the moment they find it. There’s a gatekeeping layer that runs first, and understanding it explains most of the found-but-not-cited gap.
Classification: The system first decides in milliseconds whether the prompt needs external web grounding at all.
Query fan-out: If it does, the model generates a set of internal sub-questions (called “fan-out queries”) derived from the user’s original prompt. These, not the original prompt itself, are what your content actually gets matched against.
Retrieval: The engine pulls back a batch of candidate URLs, each carrying a title, snippet, and source URL – not the full page.
Pre-read filtering: Using just that title, URL, and snippet, the model decides which pages are worth opening. Many pages are discarded here, before a single word of your content is read.
Scoring and citation: Surviving pages are opened, converted into passages, and scored for semantic alignment with the fan-out queries. Only the top-aligned passages earn a citation slot.
The critical detail is step 4. If your title and snippet don’t clearly signal what the page answers, you can be filtered out before the AI ever reads your actual content – regardless of how well-written that content is.
Ahrefs’ data backs this up directly: the maximum cosine similarity between a cited page’s title and the model’s fan-out sub-questions averaged around 0.66, meaningfully higher than for pages that were retrieved but never cited. A page can rank #1 on Google for a broad keyword and still lose the citation if its title doesn’t map onto the specific, narrower question the AI is actually trying to answer internally.
Your content might be feeding AI answers without getting any credit for it.
See exactly which of your pages are getting retrieved but skipped — and walk away with a prioritized fix list for turning them into cited, credited sources.
Get your free citation audit 30 minutes, no obligation — just a clear read on where your AI visibility stands.The Data: How Big Is the Gap, Really?
A few numbers from recent independent research put the scale of this problem in perspective.
| Finding | What It Means |
|---|---|
| ~50% of retrieved URLs never get cited (Ahrefs, 1.4M prompts) | Retrieval is not the bottleneck — evaluation is |
| ~88% of cited ChatGPT URLs come from the standard search index | Ranking is still a prerequisite, just not sufficient on its own |
| Reddit is retrieved ~16M times but cited only ~1.9% of the time | Models learn from Reddit’s consensus but rarely credit it |
| News content is cited only ~12% of the time, but cited pages skew younger | Freshness becomes the tiebreaker when relevance scores are similar |
| ~62% of citations are “ghost citations” (Semrush/Kevin Indig study) | The AI links to the domain but never names the brand |
| Only ~13% of citations pair a link with a brand mention | Dual attribution — link and name — is the rare, high-value outcome |
That last point matters as much as the found-but-not-cited gap itself. Even when your page does get cited, the AI may still describe it anonymously – “one source notes,” “according to a report” – without ever naming your brand. Semrush and Kevin Indig’s research on this “ghost citation” pattern found it accounts for the majority of all AI citations: your data gets used, your brand doesn’t get the credit. Mention-only citations, where the brand is named but no link appears, are nearly as common. Getting both a link and a name attached to the same answer is the exception, not the norm.
Platform behavior also isn’t uniform. ChatGPT leans academic – citing frequently but naming brands rarely. Gemini does the opposite, naming brands often in conversational answers while linking out far less. If your GEO strategy only tracks one platform, you’re likely missing where the actual gap is.
Six Reasons Your Content Gets Filtered Out Before It’s Ever Cited
Retrieval systems are risk-averse. Before an AI engine reuses a passage, it’s effectively asking: who’s responsible for this claim, can I lift it out of context safely, and is it clearly bounded? If the answer to any of those is unclear, the content gets treated as low-confidence background information — used to inform the answer, perhaps, but never credited.
1. Authorship is invisible or inconsistent. A generic “Team” byline, or no author at all, gives the model nothing to attribute the claim to. If the same person is described as “Founder” on one page and “Marketing Lead” on another, the model reads that as two different entities, not one. Fix it with a real name, a specific role, and identical wording used consistently across the article, the bio, and the About page.
2. The title doesn’t map to a specific question. Curiosity-driven headlines (“What You Don’t Know Could Cost You“) give the AI nothing to classify. Titles that state the topic, the object, and the outcome directly – the kind of phrasing a fan-out query would generate – get matched and pulled far more reliably.
3. The first screen doesn’t define the topic. AI systems weight the opening of a page heavily. If your intro leads with a brand story or an anecdote before stating what the page is actually about, the model may misjudge the page’s relevance before it reaches your best material.
4. Claims are unbounded. Statements like “this always works” or “most businesses don’t realize” carry no scope, and unscoped claims are easy to misapply – which makes them risky to cite. Adding the condition directly into the sentence (who, where, under what circumstances) turns a vague claim into an extractable one.
5. The content restates generic advice. If your explanation already exists, in near-identical form, across thousands of other pages the model has seen in training, there’s nothing distinctive to cite. Specific, field-level detail – the kind that comes from direct experience with a problem, not a summary of it – is what makes a passage worth attributing to you rather than paraphrasing anonymously.
6. Sections don’t stand alone. Generative engines extract fragments, not full articles. A section that depends on narrative buildup from earlier paragraphs is unsafe to lift out of context, so it gets skipped. Every H2 or H3 should function as a complete, self-contained answer to one question.
How to Fix It: A Practical Audit
You don’t need to rebuild your entire content library. Start with pages that already have retrieval demand and work through this sequence.
Step 1: Find where AI is already looking. In Google Search Console, sort informational pages by impressions. High impressions with flat or declining clicks is often a signal that AI systems are surfacing your content in summaries without sending a click-through. These are your priority audit targets.
Step 2: Run the first-screen test. Open the page and, without scrolling, ask: who’s speaking, why are they qualified, what is this page about, and who is it for? If any of those isn’t obvious immediately, restructure the opening to answer it directly – a strong BLUF (bottom-line-up-front) paragraph in the first 100 words.
Step 3: Check title alignment against real questions. Rewrite headlines to match how someone would actually phrase the question to an AI assistant, not how it reads as a clever headline. Specific, declarative titles consistently outperform curiosity-driven ones on extractability.
Step 4: Run the section-isolation test. Copy a single H2 section into a blank document. Does it define the issue, explain the cause, and give the guidance – all without needing the rest of the article for context? If not, rewrite the section so it can stand entirely on its own.
Step 5: Tighten claim precision. Scan for unscoped phrases (“usually,” “most,” “always”) and attach the missing condition directly in the same sentence.
Step 6: Add structured, verifiable proof points. Academic research on GEO from Princeton, Georgia Tech, and IIT Delhi found that adding attributed expert quotes and precise statistics were the two strongest levers for lifting a page’s visibility inside AI-generated answers – each outperforming generic fluency or tone improvements by a wide margin. Vague qualitative claims consistently underperform against specific, sourced data.
Step 7: Verify your schema matches what’s actually on the page. Structured data (Organization, Author, Article, FAQPage schema) helps AI systems parse authorship and topic quickly – but only if it matches what’s visibly on the page. Mismatched schema erodes trust signals rather than building them.
Free AEO/GEO audit
Is your content found by AI, but never cited?
We’ll run your top pages through ChatGPT, Gemini, and AI Overviews and show you exactly where the citation gap is costing you visibility.
Book your free 30-min auditTrack the Right Metrics
Standard analytics won’t show you this gap – Google Analytics and Search Console weren’t built to report on AI citations. Track these instead:
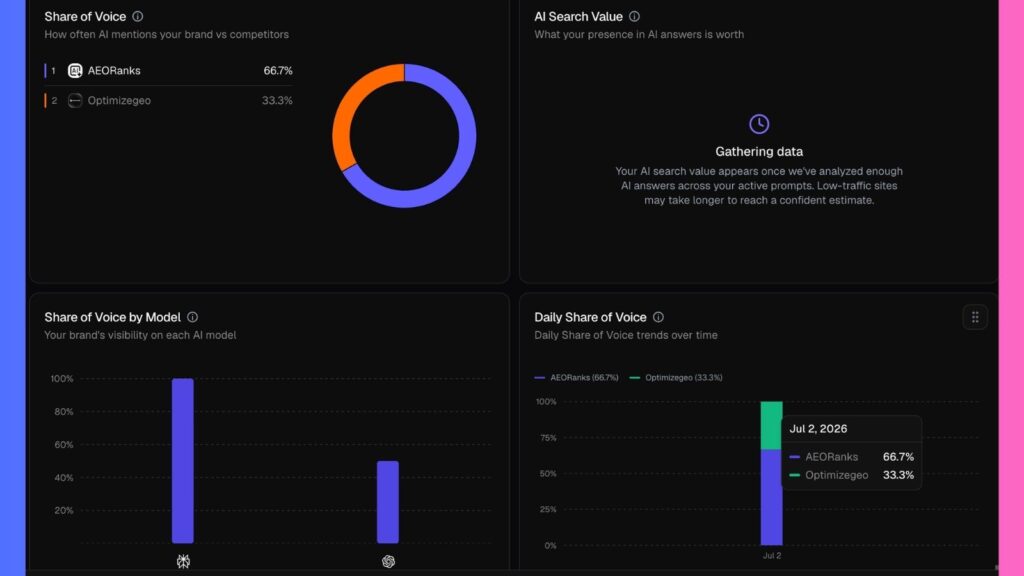
- AI Share of Voice: how often your brand is cited or mentioned across target prompts, relative to competitors.
- Retrieval-to-citation ratio: how often your content is found versus how often it’s actually cited, which isolates the exact found-but-not-cited pages worth fixing first.
- Mention rate vs. citation rate: high mentions with low citations usually means brand awareness exists but your content structure needs work; the reverse means you’re earning links without brand recognition (the “ghost citation” pattern).
- External mention velocity: unlinked brand references across forums, review sites, and communities, which feed the entity-recognition signals models use before deciding whether to cite you by name.
Tools like Ahrefs’ Brand Radar are built specifically to surface this: filter for pages with high “found in” counts but low “cited in” counts, and you get a prioritized list of exactly which pages need a content retrofit rather than a completely new asset.
What does “found but not cited” mean in AI search?
It describes a page that an AI system retrieves into its working context during a query but ultimately excludes from the final answer – no citation link, no brand mention, and no visibility to the end user.
Is a citation the same as a backlink?
No. A backlink is another website choosing to link to yours. A citation is a generative engine actively selecting your content as the direct source behind a specific claim in its answer. Both signal trust, but citations drive visibility inside the AI response itself, not just on the wider web.
Why does ranking #1 on Google not guarantee an AI citation?
Because generative engines score passages against internally generated sub-questions (fan-out queries), not just the user’s original search term. A page can dominate a broad keyword and still fail to align with the narrower, more specific question the AI is actually trying to answer.
What’s a ghost citation?
A ghost citation happens when an AI system links to your domain in its response but never names your brand – describing you instead as “one source” or “according to a report.” It delivers potential referral traffic without brand recognition.
How do I check if my content is being cited by AI?
Run your target prompts regularly through ChatGPT, Gemini, Perplexity, and Google AI Overviews, and track whether your brand appears, is linked, or is mentioned by name. Platform-level AI visibility tools can automate this tracking across dozens or hundreds of prompts at once.
Being retrieved by an AI system is no longer the finish line – it’s the starting point. The brands winning citations aren’t necessarily the ones publishing the most content; they’re the ones structuring it so it can be safely lifted, attributed, and trusted at the passage level. Clear authorship, question-aligned titles, self-contained sections, and specific, sourced claims are what separate content that gets used anonymously from content that gets credited by name.

Leave a Reply